World Models: The End of the Flat Screen Era
How AI systems are learning to simulate reality—and why it matters for your business
On February 3, 2026, Google launched Project Genie to AI Ultra subscribers. Within days, Waymo published their autonomous driving world model. NVIDIA's Cosmos platform hit production. The race wasn't just starting—it was accelerating.
For the first time, AI systems weren't just analyzing the world. They were simulating it.
After six months deep in world model architectures, competitive analysis, and production deployments, I'm sharing what actually matters—for engineers building the systems and PMs shipping the products.
Part 1: What Are World Models? (And Why Should You Care)
The Simple Answer
World models are AI systems that learn to predict what happens next in physical environments. Unlike traditional physics engines with hard-coded rules, they learn physics, spatial relationships, and dynamics from data.
The key difference: They're interactive simulators, not just video generators. You can take actions and watch the world respond.
Why This Matters
For decades, AI was trapped in "flatland"—pattern matching on 2D representations without understanding physics or space. Early robotics systems broke when lighting changed or objects moved slightly. Computer vision recognized cats but couldn't predict how they'd move.
World models break this constraint by learning:
- Spatial structure (3D geometry, object relationships)
- Temporal dynamics (how things change over time)
- Action consequences (what happens when you push, pull, or move)
Business impact: Technologies that were impossible or prohibitively expensive become viable at scale.
Part 2: The Architecture That Makes It Work
Three Core Components
1. Video Tokenization: Compression Without Compromise
Raw video is massive. World models compress it ~500x into discrete tokens while preserving spatial and temporal structure. Dreamer 4 uses 256 spatial tokens per frame—the sweet spot between quality and compute efficiency.
Why it matters: This compression ratio determines both output quality and inference cost. Get it wrong, and you either lose detail or burn money.
2. Space-Time Transformers: The Prediction Engine
Modern architectures separate spatial and temporal attention. Temporal layers appear only every 4 layers (not in every layer), dramatically cutting memory costs while maintaining coherence.
Additional tricks:
- Grouped Query Attention (share key-value heads)
- SwiGLU activations
- RoPE positional encodings
Real-world result: Dreamer 4 hits 30 FPS on a single H100 GPU—fast enough for real-time interaction and RL training.
3. Action Conditioning: The Closed Loop
This is what separates world models from video generators. The system takes actions as input and predicts what happens next. You can actually interact with generated environments.
Two approaches:
- Explicit actions (Dreamer 4): Train on labeled gameplay/robotics data
- Latent actions (Genie 3): Infer actions from consecutive frames via inverse dynamics
Why both matter: Explicit actions work when you have labels. Latent actions unlock training on massive unlabeled video datasets.

Part 4: The Competitive Landscape
Google DeepMind: General-Purpose AGI Bet
Strategy: Build the foundation layer everyone else builds on top of
Strengths:
- Real-time interactivity (modify worlds on the fly)
- Unlimited training environments for agent development
- Massive pretraining on internet video
Limitations:
- Consistency degrades after "a few minutes" (Google's phrasing)
- Physics accuracy is approximate
- Occasional impossible geometry hallucinations
The bet: World models are critical infrastructure for AGI. Create ecosystem lock-in.
NVIDIA: Industrial Precision
Strategy: Physical AI for robotics, AVs, industrial automation
Strengths:
- Tight Omniverse/Isaac Sim integration
- PhysicsBench: standardized physical consistency evaluation
- Enterprise-ready, safety-focused
Differentiation: Less magical, more rigorous. The anti-Genie approach.
Why it matters: NVIDIA is building the testing framework that determines which models are deployment-ready.
World Labs: Creative Tooling
Strategy: High-quality spatial generation + creator workflows
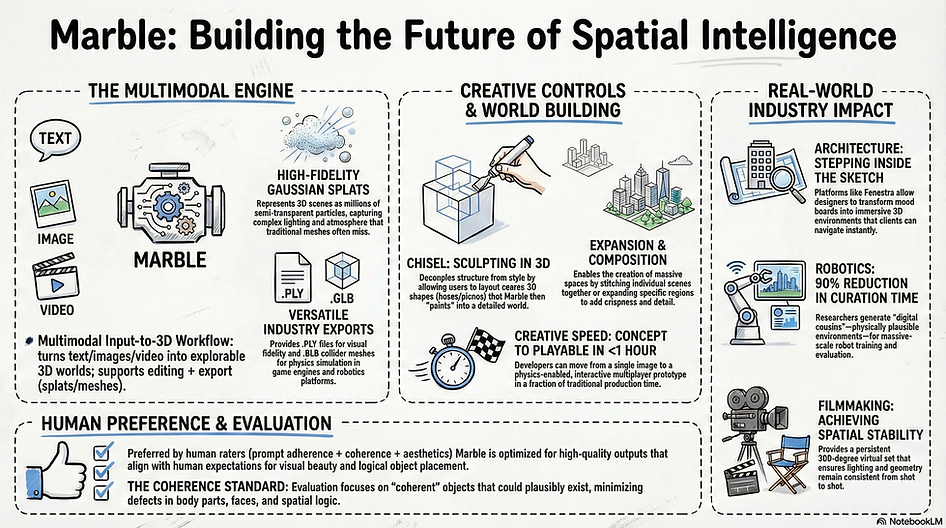
Product: Marble generates 3D Gaussian Splat worlds from images/text
Key insight: Don't be a complete simulator. Be a world generation engine that slots into existing pipelines.
Output formats:
- PLY Gaussian Splats (real-time rendering)
- GLB collision meshes (physics)
- Direct integration: Unreal Engine, Unity, Isaac Sim, VIVE Mars
Business model: Pragmatic adoption. Environment creation: weeks → minutes.
Waymo/Wayve: Vertical Specialization
Strategy: Purpose-built for autonomous driving
Requirements:
- Multi-camera geometric consistency
- Rare edge case generation (safety-critical scenarios)
- Accuracy standards far beyond gaming/creative
The lesson: General models are impressive demos. Production often requires domain specialization.
Part 5: Production Use Cases (What Actually Works)
Robotics: 90% Cost Reduction
The problem: Training manipulation requires thousands of diverse scenarios. Manual data collection is slow, expensive, dangerous.
The solution: Generate unlimited environment variations from minimal real-world captures.
Case study: Lightwheel + World Labs
- Input: Single 360° images of kitchens
- Process: Marble generation → Isaac Sim export → robot policy training
- Result: 90% reduction in environment curation time
- Bonus: Better sim-to-real transfer (more diverse training coverage)
Economics:
- Manual 3D creation: $5K-$50K per scene, weeks of work
- Marble generation: Minutes, marginal compute cost
- At 1,000+ training scenarios: ROI is obvious
Limitation: "Plausible cousins" not perfect digital twins. Good for gross motor skills (navigation), problematic for fine manipulation (assembly).
Gaming: Rapid Prototyping
The value: Accelerate iteration, not replace artists
Workflow:
- Concept art → Marble generation → Unreal Engine 5 → Playable prototype
- Test 10 environmental variations in an hour
- Invest in high-fidelity assets for winning directions
Example: Gaussian Mansion
José Tijerín: concept sketches → navigable
worlds → cinematic rail shooter with interaction mechanics
Extreme case: Rosebud AI
Text → playable multiplayer game in minutes.
Current quality limits this to indie/educational content.
Virtual Production: Hours vs Weeks
Traditional workflow: Pre-vis → 3D modeling → LED volume setup (weeks)
World model workflow:
- Generate environment from concept art (Marble)
- Import to VIVE Mars Nova
- Shoot actors on green screen with camera tracking
- Real-time composite with proper lighting/depth
Studio results: Concept to camera-ready footage in hours
Use case: Establishing shots, background plates. Not yet precise enough for hero shots requiring exact art direction.
Architecture: Spatial Communication
The gap: Clients can't understand spatial concepts from floor plans (flat) or static renders
The solution: Explorable 3D environments from sketches/mood boards
Value: Test circulation patterns, evaluate sight lines, communicate design intent at human scale
Limitation: Not construction-ready (missing: wall thickness, structural details, MEP systems). But vastly better than traditional visualization.
Healthcare & Education
- Therapeutic: On-demand exposure therapy environments for OCD/phobias (early clinical trials show promise)
- Educational: Historical recreation, spatial learning (anatomy, geography), simulation-based training
Core value: Infinite personalized scenarios at marginal cost
Part 6: Challenges
1. The Physics Hallucination Problem
What happens: Objects float. Collisions are approximate. Conservation laws violated.
Why it's a problem:
- Creative applications: Tolerable quirk
- Safety-critical robotics/AVs: Showstopper
Root cause: Models learn visual correlations, not physical laws. They generate plausible-looking physics without simulating forces/torques/constraints.
Current solution: Hybrid approach
- World models: Perception + scene generation
- Physics engines: Dynamics simulation
- Example: Marble (visuals) + Isaac Sim (physics)
Tradeoff: Works but sacrifices end-to-end elegance
2. Compute Economics
The cost:
- Dreamer 4: 30 FPS on single H100 ($30K GPU)
- Genie 3: Multiple GPUs per user for 24 FPS
Viable for:
- Offline batch generation (robotics training, architectural viz)
- Premium consumer tier ($20/month AI Ultra)
Not yet viable for:
- Mass-market consumer applications (unit economics don't work)
- Free-tier services
Business implication: Project Genie's pricing reveals the current cost ceiling
3. Consistency Breakdown
The problem: Coherence lasts "a few minutes" (Google's careful phrasing)
What happens: Objects drift, geometry warps, world forgets previous state
Technical challenge:
- Finite transformer context windows
- Attending over thousands of frames is computationally prohibitive
- Current: Sliding windows + occasional long-context layers
Not yet solved: Global consistency for persistent worlds
Promising directions: Learned compression of historical states, hierarchical representations (still research-stage)
4. The Controllability Gap
What users want: "Make this room brighter," "Add a window here," "Change time of day"
What they get: Opaque prompts → regeneration → hope it works
What's missing:
- Explicit scene graphs
- Object-level manipulation
- Separation of geometry from appearance
Professional tool requirement: Move object 3 units on X axis, rotate 15°, adjust material roughness to 0.7
Current reality: "Vibes-based" generation with imprecise prompt-driven output
Path forward: Either breakthrough in interpretable representations OR hybrid workflows (generation + traditional 3D tools)
Part 7: What's Next
- Robotics-specific models
- Autonomous driving simulations
- Gaming-optimized models
- Architecture/design models
- Medical simulation models
A. Platform vs Tooling Plays
Two viable paths:
- Platform (Google/NVIDIA): Infrastructure layer (AWS for spatial intelligence)
- Tooling (World Labs): Integrated features in existing platforms (Unity/Unreal plugins)
B. Data Moats Matter
Proprietary domain data wins:
- Driving scenarios (Waymo/Wayve)
- Manipulation demonstrations (robotics companies)
- Architectural plans (design firms)
Watch: Partnerships and data acquisition as competitive levers
C. Open Model Ecosystem
NVIDIA Cosmos released as open weights. Signal: Foundation world models may follow LLM open playbook.
Impact:
- Accelerates application development
- Increases safety challenges
Critical: Licensing terms for safety-critical applications
Conclusion: We're Not Watching. We're Building.
The flat screen era is over. AI systems don't just analyze reality—they generate and interact with spatial environments.
What's solid:
- Transformer architectures proven for real-time, high-fidelity generation
- Discrete tokenization enables efficient compute
- Action conditioning creates true interactivity
- Space-time attention scales effectively
What's still broken:
- Consistency (minutes not hours)
- Controllability (prompts not precision)
- Physics accuracy (correlations not laws)
- Compute costs (premium tier only)
The reality: These are engineering problems, not fundamental research blockers.
The opportunity: Certain domains see rapid adoption now (robotics, virtual production, gaming prototyping). Others wait for technical maturation (consumer VR, safety-critical AVs).
The certainty: Manually crafting every 3D environment is ending. World models amplify human creativity:
- Concept artists: Weeks → hours
- Robotics teams: Dozens of environments → thousands
- Filmmakers: Full VFX crew → laptop + green screen
For anyone building spatial computing, robotics, or interactive AI: world models are now essential infrastructure.
Resources
Frontier “foundation world models”
- DeepMind — Genie 2 (2024): https://deepmind.google/blog/genie-2-a-large-scale-foundation-world-model/
- DeepMind — Genie 3 (2025): https://deepmind.google/blog/genie-3-a-new-frontier-for-world-models/
Industry platformization (world models as an API)
- World Labs — Announcing the World API (Jan 21, 2026): https://www.worldlabs.ai/blog/announcing-the-world-api
Simulation workflow (world generation → robotics sim)
- NVIDIA — Isaac Sim + World Labs Marble workflow (Dec 17, 2025):
https://developer.nvidia.com/blog/simulate-robotic-environments-faster-with-nvidia-isaac-sim-and-world-labs-marble/
Why “better conditioning” matters (prompt fidelity / captions / actions)
- OpenAI — “Improving Image Generation with Better Captions” (DALL·E 3 paper):
https://cdn.openai.com/papers/dall-e-3.pdf - OpenVLA: An Open-Source Vision-Language-Action Model : https://arxiv.org/pdf/2406.09246
Multimodal grounding (vision-language deep fusion example)
- CogVLM paper: https://arxiv.org/abs/2311.03079
Foundations (world models in RL)
- “World Models” (Ha & Schmidhuber, 2018): https://arxiv.org/abs/1803.10122
- PlaNet (Learning latent dynamics for planning from pixels, 2018): https://arxiv.org/abs/1811.04551
- DreamerV3 (Mastering diverse domains through world models, 2023): https://arxiv.org/abs/2301.04104