VL-JEPA: AI That Thinks in Meaning, Not Words
Why Predicting Meaning Instead of Tokens Is Architecturally Interesting
Most vision-language demos online focus on one thing: showing that a model can describe an image.
That is not what interested me here.
What interested me was a more basic architectural question:
Why should a model generate answer text token-by-token at all if the real goal is to understand the answer semantically?
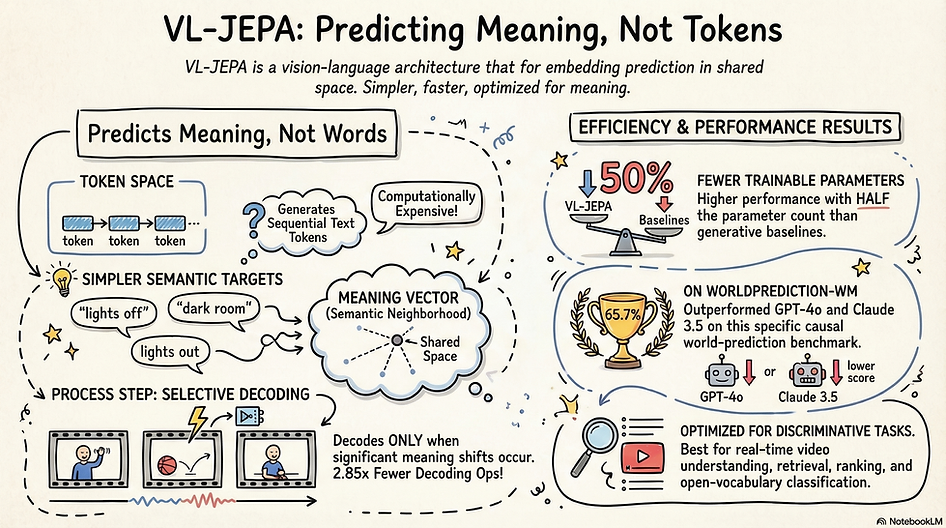
That question sits at the center of VL-JEPA — Meta FAIR’s Vision-Language Joint Embedding Predictive Architecture. Instead of predicting an answer as a token sequence, VL-JEPA predicts the embedding of the answer. That shifts training from token reconstruction to semantic prediction.
The problem with classical vision-language generation
Most vision-language models answer by generating text autoregressively, one token at a time:
(image, question) -> token 1 -> token 2 -> token 3 -> ...
This is powerful, but it has three practical drawbacks:
- It ties meaning to wording: semantically similar answers are treated as different token sequences.
- It is sequential at inference: longer answers require more decoding steps, which increases latency.
- It overuses language generation: many real tasks need retrieval, ranking, or answer selection rather than full-text output.
In many applications, text generation is best treated as an output layer, not the core reasoning mechanism.
What is VL-JEPA
VL-JEPA replaces token prediction with embedding prediction.
The model learns:
(image/video, query) -> predicted answer embedding
The answer text is separately encoded into a semantic target space, and the predictor is trained to land near the correct target embedding.
That changes the learning problem in a useful way.
Instead of trying to reconstruct one exact wording, the model tries to reach the right region of meaning-space.
This is the core reason JEPA-style systems are interesting:
they move prediction into representation space.
How VL-JEPA works
VL-JEPA is trained on triplets ⟨visual input, text query, text target⟩ and has four parts:
- X-Encoder maps the image or video into visual embeddings
S_V. - Predictor takes
S_Vplus the query textX_Qand predicts the target answer embeddingŜ_Y. - Y-Encoder maps the ground-truth answer text
Yinto the target embeddingS_Yin the same semantic space. - Y-Decoder is optional at inference and converts the predicted embedding back into readable text when needed. It is not part of the main training path.
Training uses bi-directional InfoNCE to align the predicted embedding Ŝ_Y with the target embedding S_Y while preventing collapse of the embedding space.
Why VL-JEPA is important
VL-JEPA matters because it targets several real weaknesses of classical autoregressive VLMs:
- It reduces dependence on exact phrasing.
Different valid answers can map to nearby points in embedding space instead of being treated as unrelated token sequences. - It cuts sequential decoding overhead.
Classical VLMs must decode token by token before revealing the answer, which adds latency. VL-JEPA can operate directly in embedding space and decode only when text is needed. - It fits retrieval, classification, and discriminative VQA naturally.
The shared embedding space supports open-vocabulary classification and cross-modal retrieval with one unified architecture. - It is better suited for real-time video applications.
Because embeddings can be produced continuously, VL-JEPA supports selective decoding, which is useful for streaming and event-driven settings. - It points toward latent-space multimodal reasoning.
The paper explicitly positions VL-JEPA as a foundation for future work on shared multimodal latent reasoning, not as a universal replacement for all generative VLMs.
Real-world applications
1. Real-time assistive vision
Wearables and edge devices can use semantic prediction to monitor scenes continuously, decoding language only when a user-facing explanation is needed.
2. Robotics and embodied AI
Compact semantic representations can support downstream perception, state understanding, and decision-making in embodied systems.
3. Retrieval-first systems
In search, monitoring, and review workflows, ranking relevant answers by meaning is often more useful than generating long text.
4. Video understanding pipelines
Selective decoding is useful when semantic state changes are sparse relative to raw frame arrival rate.
5. High-stakes domains
In medical, industrial, and safety settings, discriminative retrieval and structured evidence matching can be more appropriate than unconstrained generation.
Future scope of VL-JEPA
VL-JEPA is promising, but it is still an early architectural direction rather than a complete replacement for generative VLMs.
- Broader evaluation: the paper explicitly notes that VL-JEPA still needs stronger evaluation on reasoning, tool use, and agentic behaviors.
- Scaling studies: the authors report clear gains from scale, but do not fully explore parameter and dataset scaling.
- Latent-space reasoning: a major next step is extending VL-JEPA beyond one-shot embedding prediction toward richer multimodal latent reasoning, including visual chain-of-thought.
- Stronger streaming systems: selective decoding is one of VL-JEPA’s most practical ideas, and future work will likely refine when to stay in embedding space versus when to decode to text.
- Closer connection to world models: since VL-JEPA inherits ideas from the JEPA family, an important long-term direction is tighter integration with video prediction, planning, and embodied AI systems.